Text: "I THINK WHAT IS BEING SHOWN IS THE SYSTEM FOR THE HEART"
Ground_truth
Proposed system
ParallelWavGan
WorldVoc
Text: "THESE CIRCUITS ARE CLOSED AND THE LIGHT BULB SHOULD BE LIGHTING UP BUT FOR SOME REASON IT'S NOT
"
Ground_truth
Proposed system
ParallelWavGan
WorldVoc
Girl Speaker:
Text: "I THINK IT WOULD GET BRIGHTER TO BREAK THE BULB OR IT WOULDN'T WORK"
Ground_truth
Proposed system
ParallelWavGan
WorldVoc
Text: "I MEAN LIKE IT POWERS MOSTLY EVERYTHING"
Ground_truth
Proposed system
ParallelWavGan
WorldVoc
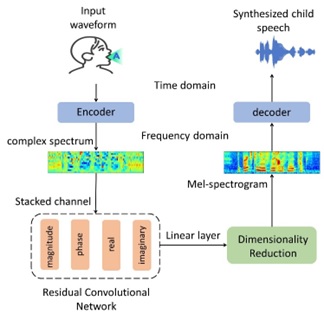
Visualization
The image below demonstrates The comparison of Mel spectrograms and F0 values between the ground truth and three models: (b) AutoVocoder, (c) ParallelWavGan, and (d) WORLD Vocoder for both Boy and Girl.